
Merkle Trees: The Backbone of Blockchain Data Verification
When working with Merkle trees, a structure that repeatedly hashes pairs of data to create a single root hash. Also known as hash trees, they let you prove any piece of data belongs to a larger set without revealing the whole set. Blockchain, a distributed ledger that records transactions in linked blocks relies on this exact trick to keep each block tamper‑proof. And the magic starts with cryptographic hash, a one‑way function that turns any input into a fixed‑size string – the glue that binds every leaf to the root.
Think of a Merkle tree as a family tree, but instead of people it’s chunks of data. Each leaf node holds the hash of a raw data block – maybe a transaction, a file chunk, or a smart‑contract state. Those leaf hashes pair up, get hashed again, and form the next level. This process repeats until you reach the topmost hash, the Merkle root. The root acts like a digital fingerprint for the entire dataset. If even a single bit changes anywhere below, the root changes, instantly signalling tampering.
Why does this matter for blockchain users? Because nodes don’t need to store every transaction to verify new blocks. They only keep the Merkle root in the block header. When a lightweight client wants to confirm a transaction, it asks for a Merkle proof – a short list of sibling hashes that, when combined with the transaction’s own hash, rebuilds the root. This proof is tiny, often just a few hundred bytes, yet it offers the same security as downloading the whole chain.
Besides blockchain, Merkle trees shine in any scenario demanding data integrity, assurance that data hasn’t been altered unintentionally or maliciously. File‑sharing services use them to verify large files split across peers. Distributed databases employ them to synchronize shards without sending full records. Even software updates can include a Merkle root so devices can verify each patch piece instantly.
Key Benefits and Practical Uses
Speed is the first win. Verifying a Merkle proof takes logarithmic time relative to the number of items – far faster than scanning an entire list. Memory savings are another big plus; you only need to keep the current root and a few sibling hashes, not the whole dataset. Security-wise, the reliance on strong cryptographic hash functions means forging a valid proof without the original data is computationally infeasible.
In crypto, Merkle trees enable advanced features like light client wallets, sharding, and cross‑chain bridges. Sharding splits a blockchain into smaller pieces, each with its own Merkle root, allowing parallel processing while preserving overall consistency. Cross‑chain bridges use Merkle proofs to lock assets on one chain and mint equivalents on another, all without trusting a central party.
Beyond finance, the tech is used in supply‑chain tracking, where each step of a product’s journey adds a hashed record to a Merkle tree. Auditors can request a proof for a specific batch without seeing the entire history, protecting privacy while ensuring traceability. Cloud storage platforms also embed Merkle roots in metadata to let users verify that their uploaded files remain unchanged over years.
Implementing a Merkle tree is straightforward in most programming languages. You start with an array of data blocks, hash each block, then iteratively combine pairs until you produce the root. Many libraries already handle the heavy lifting, offering functions to generate both the tree and the accompanying proofs. When choosing a hash algorithm, stick with proven ones like SHA‑256 or Keccak‑256 – they provide the collision resistance needed for trustworthy roots.
There are a few variations worth knowing. A binary Merkle tree pairs exactly two children per node, but you can also build an n‑ary tree where each node combines more than two hashes, reducing tree height. Sparse Merkle trees map a huge address space (like 2^256 possible keys) into a compact structure, useful for blockchain state representations where most slots are empty.
One common confusion is mixing Merkle trees with Merkle–Damgård constructions, the underlying method many hash functions use. They’re related but not the same: the former is a data structure, the latter is a way to extend a hash function to arbitrary lengths. Keeping that distinction clear helps avoid design mistakes, especially when you try to build custom proof systems.
When evaluating a project that claims to use Merkle trees, ask a few practical questions: What hash algorithm backs the tree? How large are the proofs they generate? Do they support updates without rebuilding the entire tree? Answers to these guide you toward secure, efficient implementations.
In short, Merkle trees turn massive, mutable datasets into compact, immutable fingerprints. They give blockchain developers a reliable way to prove inclusion, enable light client operation, and open doors to scaling solutions. At the same time, they empower non‑crypto fields to verify data integrity without costly bandwidth or storage.
Below you’ll find a curated collection of articles that dive deeper into every angle mentioned here – from tax implications in different regions to real‑world airdrop case studies, exchange reviews, and energy‑sector blockchain applications. Whether you’re a trader, developer, or regulator, the posts will give you concrete examples of how Merkle trees are shaping the crypto landscape today.
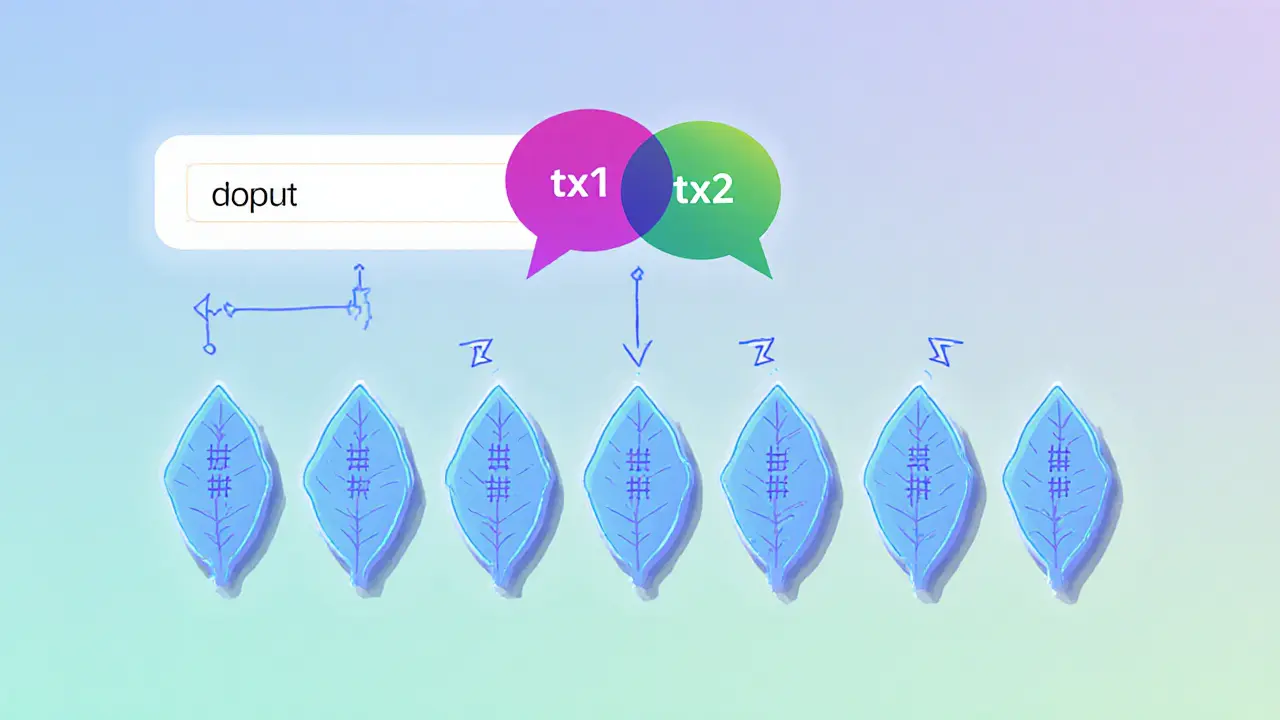
Learn how Merkle trees work in blockchain, why they boost security and efficiency, and get practical tips for building and verifying Merkle proofs.
Categories
 Finance
Finance
Archives
Recent-posts

HeroesTD (HTD) Airdrop 2025: What We Know About the Coinmarketcap Event and Token Details
Dec, 11 2025
PHA Airdrop by Phala Network: How to Claim 30 PHA Tokens and What You Need to Know
Dec, 28 2025

AST Unifarm Airdrop by AST.finance: What You Need to Know
Oct, 4 2025
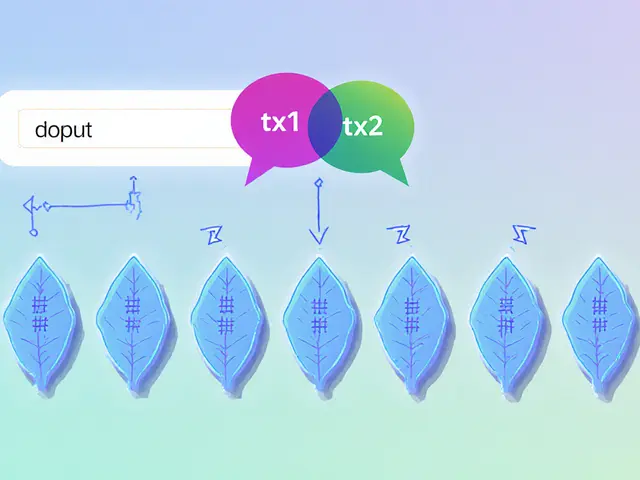
Merkle Trees Explained: How Blockchain Uses Hash Trees for Secure Verification
Nov, 11 2024

GMEE Airdrop by GAMEE: Full Details, Status, and WATCoin Update 2026
Mar, 25 2026